
Ohne den Begriff Big Data scheint es nicht mehr zu gehen. Aber was verbirgt sich eigentlich dahinter? Man kann sagen, Big Data hat mit riesigen Datenmengen zu tun, die ohne großes Zutun einfach so generiert werden, automatisiert analysiert werden, marktmäßig genutzt werden und den Datenschützern immer wieder Kopfzerbrechen bereiten. Schon die Bezeichnung Big Data bringt zum Ausdruck, dass damit eine neue Qualität erreicht ist.
Data Science gab es schon immer
Daten sind allgegenwärtig. Charakteristika, Ereignisse, Zusammenhänge – alles lässt sich irgendwie abbilden. Die zahlenmäßige Abbildung erlaubt Organisation, Aggregation und Vergleiche. Ob es darum geht, Steuern zu erheben oder allgemeine Gesetzmäßigkeiten zu identifizieren; das Bedürfnis nach höher, besser, weiter, hat Menschen schon immer dazu angetrieben Daten zu sammeln und zu analysieren. Eines der ältesten und immer noch fortbestehenden Beispiele dafür sind Kirchenregister, die lange auch als Personenstandsregister verwendet wurden. Beispiele für einzelne Volkszählungen (Zensus) gehen sogar bis in die Zeit vor Christus zurück. Eine der ersten wirtschaftlichen Anwendungen systematischer Datenanalysen war die Ertragsmaximierung in der Landwirtschaft. Auf diesen Wurzeln fußt die moderne Volkswirtschaftslehre.
Die rein analoge Schriftform erschwerte die Sammlung und Auswertung. Die Hilfsmittel wurden jedoch immer weiter entwickelt, um die Datenanalyse besser und effizienter zu gestalten. Zunächst gab es ausgeklügelte Zählsysteme und Rechenmaschinen, schließlich den Computer. So begann die Mechanisierung von Volkszählungen bereits Ende des 19. Jahrhunderts vor dem Computerzeitalter.
Das Big in Big Data
Seit den 1960ern gibt es den Begriff von Big Science. Damit wurden Forschungsprojekte und Methoden benannt, die während des zweiten Weltkriegs entwickelt worden waren. Darunter fallen das Manhattan Project, Weltraumstationen, die ersten Computer, sowie Teilchenbeschleuniger. Von der Lebenswelt der meisten Menschen waren diese Entwicklungen jedoch sehr weit entfernt, geradezu abgehoben. Big markiert genau dies. Es zeigt in eine Richtung (größer als bisher), bleibt aber undefiniert und zwar gerade weil es den bekannten und gewohnten Rahmen verlässt. Big ist relativ und markiert eine sprunghafte Veränderung, deren Möglichkeiten und Folgen, basierend auf den Erfahrungen der bisherigen Lebenswelt, nicht abzuschätzen sind. Es ist also kein einfaches mehr als, keine rein quantitative Veränderung. Die Qualität verändert sich.
Die drei V’s
Der Sprung bei Big Data lässt sich an drei maßgeblichen Dimensionen festmachen, die im Englischen unter 3V zusammengefasst werden:
- Volume, also Datenmenge
- Velocity, also Geschwindigkeit und
- Variety, also Vielfältigkeit oder Komplexität.
Insbesondere die Datenmenge, welche sich zum Teil aus den beiden anderen Faktoren ergibt, ist in Dimensionen gewachsen, die wir im Einzelnen kaum denken können. Ohne digitale Technologien hätten wir weder die Möglichkeit solche Daten – eben Big Data – zu sammeln, noch sie in einer sinnvollen Weise auszuwerten; nicht einmal, wenn wir diesem Vorhaben unsere gesamte Lebenszeit widmeten. Deutlich wird das wenn man die Entwicklung der gängigen Speicherkapazität anhand der Länge einer Playlist nachvollzieht.
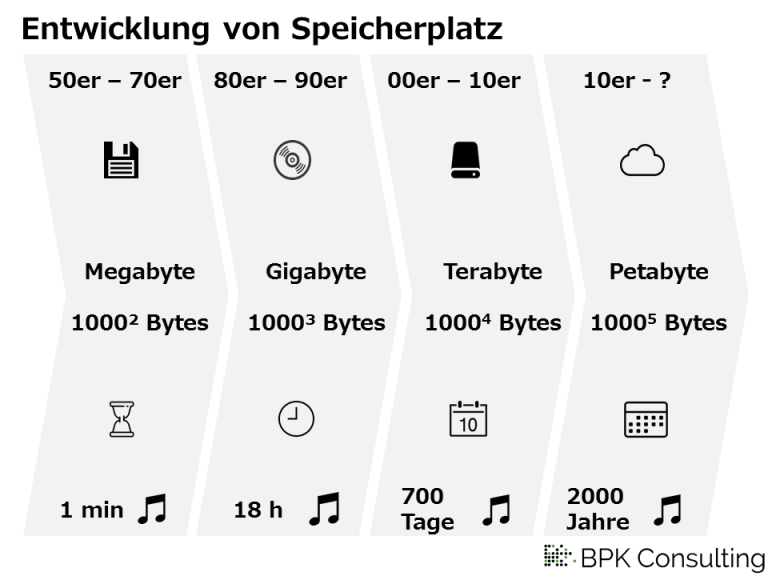
Mehr als in ein Leben passt
Während eine Playlist von 700 Tagen zwar bereits groß ist, so ist die Menge immer noch greifbar, mindestens vorstellbar. Eine Playlist bei der es 2000 Jahre braucht, bis sie einmal komplett abgespielt ist, übersteigt ganz klar unseren menschlichen Horizont. Weitere praktische Beispiele zur Einordnung der Dateigrößen beschreibt Joel Lee.
Google verarbeitet täglich mehr als 20 Petabytes an Daten, also dem Äquivalent von 40 000 Jahren Musik. An diesen Zahlen wird deutlich, mit welcher Geschwindigkeit Daten heutzutage generiert und verarbeitet werden können. Ursprünglich war die Erhebung jedes einzelnen Datenpunktes händisch zu erledigen. Heute senden beispielsweise Smartphones automatisiert Hintergrunddaten zur Nutzung, wie der Standort, die dann gleich per Algorithmus ausgewertet werden.
Daten sind mehr als Zahlen
Die klassische Vorstellung ist, dass Daten als Zahlen in Tabellen oder in Form von Datenbanken vorliegen, also eine riesige Excel-Tabelle. Mittlerweile wird jedoch alles was wir digital von uns geben als Datenpunkt oder Datenset betrachtet: Texte aus Chats und von Homepages, Fotos, Audio- und Videodateien, soziale Netzwerkverbindungen, Standortdaten, usw. Hinzu kommen Daten, die mittelbar generiert werden, zum Beispiel Sensordaten, die Autos an den Hersteller zurücksenden, sowie Datensätze die andere über einen sammeln, zum Beispiel die Schufa. Diese Vielfalt stellt das dritte Merkmal von Big Data da.
Ob Big Data nun solche Daten sind, die mindestens eines der genannten Kriterien erfüllen oder ob alle drei Kriterien gleichermaßen vorliegen müssen; darüber herrscht Uneinigkeit. Andere Quellen sprechen sogar von 5 V’s oder noch mehr. Eine genaue Definition für Big Data lässt sich mit dem heutigen Wissenstand also nicht geben, vielmehr beschreibt der Ausdruck ein Phänomen unserer Zeit, das sich lohnt näher zu betrachten.
Literaturnachweis
Aronova, E., Christine Oertzen, C., Sepkoski, D. (o. J.). Max-Planck-Institut für Wissenschaftsgeschichte. Die Geschichte von Big Data. www.mpiwg-berlin.mpg.de/de/node/7455